How Post Edits Become Writing Instructions: Bloomberry's Voice Learning Pipeline
How does an AI learn your voice? Not from a style guide you write. From the structural fingerprint it extracts from your actual posts — and from every edit you make to its generated output.
By Sadok Hasan

Short answer: Bloomberry learns your writing voice by analyzing your posts, edits, structure, vocabulary, and formatting patterns. Instead of generating generic AI content, it builds a reusable voice model that gets more accurate every time you edit its output. See also: AI that learns your voice and the AI writing patterns database it is trained to avoid.
Most AI writing tools do one of two things. They ask you to describe your writing style — "professional but conversational, avoid jargon, use short sentences." Or they ask you to select from a list of preset tones. "Direct. Empathetic. Formal."
Neither of these works.
The problem is not that AI models cannot follow style instructions. The problem is that the instructions you give are never precise enough to override the model's defaults. "Short sentences" means something different to you than it does to the model. "Direct" is interpreted through the lens of the model's training, which has seen thousands of examples of what "direct" looks like across different writers.
The output sounds like a reasonable approximation of what you described. It does not sound like you.
Why the gap exists
Bloomberry's AI Dialects research identified something that explains this precisely: every major AI model has a dominant structural voice. ChatGPT defaults to a motivator cadence — short, punchy, framework-heavy, calls-to-action embedded throughout. Claude defaults to a philosopher register — longer sentences, nuanced framing, a tendency to sit with complexity rather than resolve it quickly.
These are not just vocabulary choices. They are structural patterns: how sentences connect, how arguments build, how ideas are introduced and closed. When you ask an AI to "write in my style" using a prompt instruction, you are fighting against a structural default with a loose description.
The only reliable counter-signal is your actual writing. Not a description of how you write. The writing itself.
What a voice profile actually is
A voice profile is not a style guide. It is a structural fingerprint extracted from your actual posts.
The fingerprint includes:
Sentence length distribution. Do you write in short punchy fragments — five words, eight words, twelve words? Or in longer analytical sentences that build through subordinate clauses and qualification? The average and variance both matter. A post where every sentence is roughly the same length sounds different from one where short and long sentences alternate.
Argument structure. Do you lead with data and move to implication? Start with a contrarian claim and then build the evidence? Open with a personal story and zoom out to a broader pattern? These are structural choices that repeat across your best posts — and that a model can be trained to replicate.
Opening patterns. Your first sentence is your most important structural signal. How do you open? With a bold claim, a rhetorical question, a specific named detail, a counter-intuitive statement? The model needs to see real examples, not a description.
Closing patterns. How do you end? With a call to action, a quiet observation, a question back to the reader, a single punchy line that crystallizes the argument? Most AI defaults end with a motivational resolution. If that is not how you write, the voice profile needs to override it.
Vocabulary clusters. Your recurring terms, the specific phrases you use for concepts you return to frequently, the words you never use. These are fingerprint-level details that no style description captures.
Bloomberry extracts all of these from your writing samples — not by having you fill out a form, but by analyzing the posts themselves.
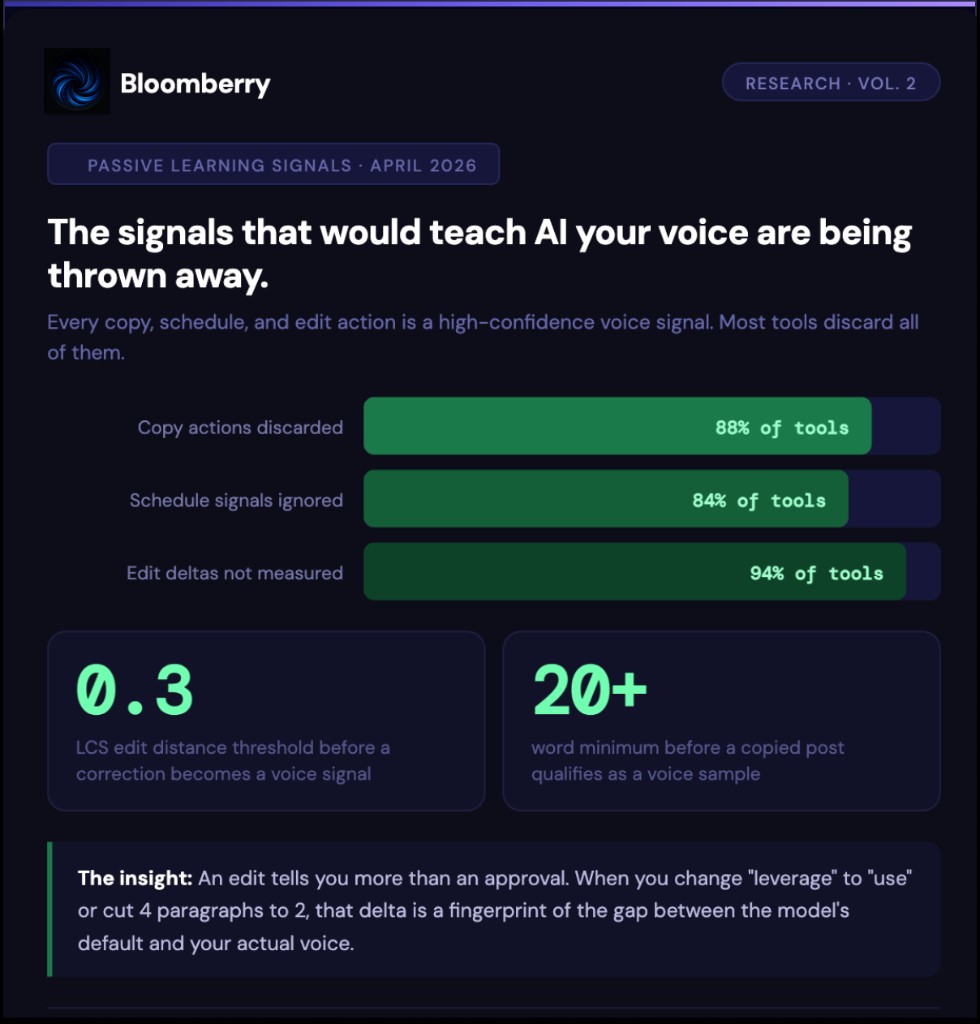
How the pipeline works
There are three phases, and they are additive. Each adds new signal on top of the previous one.
Phase 1: Seed samples
You paste your best LinkedIn posts. Five is enough to start. Ten or more gives the model more structural variety to learn from.
Bloomberry's extraction runs at the sentence and paragraph level — not just counting words, but identifying the structural moves you make. Opening types. Paragraph break frequency. How often you use data versus narrative. Whether you use bullet points, and if so how many items per list and whether they are phrases or full sentences.
The immediate output is an injection block that gets prepended to every generation: a structured description of your voice patterns at the level of actual code the model can follow, not a style description a human would write.
At this stage, Bloomberry also directly includes excerpts from your samples as "format references" — real examples of how you write that the model can pattern-match against. Describing a style is far less powerful than showing the model an example of it.
Phase 2: Edit learning
Every time you edit a generated post, that edit is a training signal.
The specific mechanism matters. Bloomberry does not just note that you edited the post — it captures the delta between what the model wrote and what you kept. That delta is the highest-confidence voice signal there is. It is not what you said you want. It is what you actually chose.
When you delete an AI-typical hedge opener and replace it with a direct claim, that is a signal about your opening style. When you shorten a paragraph from three sentences to one, that is a signal about your preferred rhythm. When you replace "leverage" with "use," that is a vocabulary signal that gets added to your word preference list.
These edit signals are stored as voice samples with the highest priority — they are surfaced to the model before your original seed samples, because they represent a revealed preference rather than a described one.
The practical effect: the more you use Bloomberry and edit its output, the more precisely it learns the gap between what the model produces by default and what you actually want. You do not have to re-prompt. You do not have to update your style description. Every edit trains the profile automatically.
Phase 3: Publish signals
Posts you schedule and publish are a third signal type. A post you liked enough to put on your LinkedIn is a higher-confidence endorsement than a post you generated and did not use.
Bloomberry stores published posts as voice samples to capture the output that made it to your audience — the writing that passed your quality bar.
Why this is different from "just prompt it better"
The most common alternative people try is more detailed prompting. "Write in short sentences. Lead with data. Never use the phrase 'in today's landscape.' Match the style of my previous post [paste]."
This works for one generation. In the next session, you start over. The model has no memory of your previous instruction. You are rebuilding the voice from scratch every time.
Bloomberry's voice profile is session-independent. It is loaded on every generation without you doing anything. You never have to re-explain yourself.
It also gets more accurate over time without any additional work from you. The edit learning pipeline means the profile improves automatically as you use the product. A tool you have used for three months with regular edits will generate significantly more accurate voice matches than one you set up yesterday — not because you updated anything, but because the usage history provides an increasingly precise picture of the gap between model defaults and your actual preferences.
What this looks like in practice
The clearest way to see the difference is to compare outputs.
Before any voice profile, Bloomberry generates competent AI content. It will have the structural tells that our research identifies as AI fingerprints — hedge openers, tricolon lists, clean resolution closers.
After 5 seed samples, the output starts matching your structural patterns. If you write in short fragments, the fragments appear. If you lead with data, the posts lead with data. If you never use bullet points, the bullets are gone.
After 14+ samples and regular edit learning, the output covers your specific argument patterns and vocabulary. The posts sound like you wrote a first draft and edited it once — not like an AI wrote them and you didn't touch them.
The AI Sentence DNA framework we identified in Vol. 1 is what the voice profile is overriding: the structural defaults the model brings to every generation. The voice profile is the counter-DNA — your specific patterns that replace those defaults.
The bigger picture
Voice learning is not a product feature. It is a solution to the fundamental problem in AI writing.
The problem is not that AI writes badly. The problem is that AI writes consistently well in a voice that is not yours — and that consistency is more recognizable and less authentic than imperfect human writing.
The solution is not better prompting. It is a structural fingerprint that gives the model something to write from instead of writing from its defaults.
The distribution gap we have written about is a consistency problem: most people stop posting before the compounding begins. The voice learning pipeline is how Bloomberry makes consistency sustainable — because the output requires less editing, which means less friction, which means more posts actually get published.
Build your voice profile free — it takes about 5 minutes to seed, and it lasts as long as you use the tool.
Related: How we use Claude Haiku to stop Gemini from hallucinating · The Fidelity Judge · AI that learns your voice · AI writing patterns database
Ready to write sharper?
Bloomberry turns your ideas into publish-ready thought leadership.
Try Bloomberry free